
۱۲ مرداد تحلیل رگرسیونی (رگرسیون خطی)

تحلیل رگرسیونی یکی از ابزارهای آماری است که کاربرد وسیعی در اقتصادسنجی، علوم زیستی،هواشناسی، امور مالی و … دارد. این تکنیک روشی ساده را برای بررسی و تعیین روابط بین متغیرها به کار می برد. در بحث روابط بین دو متغیر ضریب همبستگی به عنوان آماره ای برای سنجش میزان و جهت رابطه خطی بین دو متغیر معرفی شد. حال می خواهیم معادله ای بیابیم که این رابطه را با مدل ریاضی تبیین کند. در این روش با استفاده از الگوی همبستگی، مدلی برازش داده شده که از آن برای پیش بینی مقدار یک متغیر از روی مقادیر سایر متغیرها استفاده می شود.
برای تحلیل رگرسیونی مراحل زیر را میتوان در نظر گرفت:
- بیان مسئله و انتخاب متغیرهای مناسب
- تشخیص الگوی مناسب و برازش بهترین مدل
- اعتبار سنجی مدل برازش شده
بیان مسئله(Problem Statement)
اولین و مهمترین گام در رگرسیون، طرح مسئله است. هدف از تحلیل رگرسیونی میتواند ارزیابی اهمیت هر یک از متغیرهای مستقل برای تحلیل اثرات خط مشی بوسیله تغییر مقادیر این متغیرها یا پیش بینی مقادیر متغیر پاسخ برای هر مجموعه معلوم از داده ها باشد. مسئله ای که بد تعریف شود یا درست فرمول بندی نشود به انتخاب مجموعه متغیرها و روش آماری نامناسب منتهی می شود. پس از انتخاب متغیرهای مناسب به گردآوری داده ها از زمینه مورد مطالعه پرداخته می شود.
برازش مدل(Model Fitting)
تشخیص شکل الگویی که مجموعه متغیرها را در مدل بهم مربوط می سازد مرحله بعدی در تحلیل رگرسیونی است. اگر بتوان مدل برازش داده شده را به صورت معادله خطی نوشت، چنین مدلی را رگرسیون خطی و در غیر این صورت رگرسیون غیر خطی می نامند. رگرسیون خطی با توجه به تعداد متغیرهای پیش گو در مدل ممکن است ساده یا چندگانه باشد.
در رگرسیون خطی چندگانه به ارزیابی رابطه چند متغیر مستقل یا پیش گو با متغیر Y می پردازد. (رگرسیون چندگانه و رگرسیون چند متغیره متفاوت است. در اولی تعداد متغیرهای پیشگو بیش از یکی است و در دومی تعداد متغیرهای پاسخ. در این مقاله صرفاً در مورد رگرسیون تک متغیره بحث می شود). متغیرهای پیش گو را با X نشان داده و متغیر Y را که وابسته به مقادیرمتغیر پیش بینی کننده بوده و مقدار ان تصادفی است، متغیر پاسخ می نامند. اگرچه در رگرسیون متغیر پیشگو را متغیر مستقل نیز می نامند ولی در عمل به ندرت پیش میاید که متغیرهای پیشگو مستقل از یکدیگر باشند.
| انواع تحلیل رگرسیونی | شرایط |
| خطی | معادله رگرسیونی بر حسب پارامترهای مدل نسبت به متغیر پاسخ، خطی است |
| غیر خطی | برخی پارامترها به طور غیر خطی در مدل ظاهر می شوند |
| ساده | نوعی از رگرسیون خطی که تنها یک متغیر پیشگو در مدل وجود دارد |
| چندگانه | نوعی از رگرسیون خطی که دو یا چند متغیر پیشگو در مدل وجود دارد |
| یک متغیری | تنها یک متغیر پاسخ کمی درمدل خطی وجود دارد |
| چند متغیری | دو یا چند متغیر پاسخ کمی در مدل خطی وجود دارد |
| پارامتری | تعداد پارامترهای مدل متناهی است |
| شبه پارامتری | پارامترهای مدل نامتناهی ولی شمارا است |
| ناپارامتری | پارامترهای مدل ناشمارا است |
| پویا | رگرسیون دینامیک که داده ها خود همبسته هستند |
| لجستیک | متغیر پاسخ دوجمله ای است |
| پواسون | متغیر پاسخ شمارشی است |
الگوی رگرسیون خطی چندگانه به این صورت بیان میشود:
![\[Y_j =\beta_0 + \beta_1 X_{1j} +\dots +\beta_p X_{pj} + \epsilon_j; \quad j=1, 2, \dots, n. \]](https://amariran.com/wp-content/ql-cache/quicklatex.com-b974210a65a6252669856b710a99a00c_l3.png "Rendered by QuickLaTeX.com")
که در آن  ها پارامترهای مدل یا ضرایب رگرسیونی هستند. که باید با توجه به داده ها برآورد شوند.
ها پارامترهای مدل یا ضرایب رگرسیونی هستند. که باید با توجه به داده ها برآورد شوند.  خطای تصادفی است که پراکندگی در تقریب را نشان میدهد و به آن مقادیر باقی مانده Residuals گویند. این مقدار حاصل اختلاف بین مقادیر مشاهده شده و مقادیر پیش بینی شده با مدل در نمونه تصادفی است. در این تکنیک ابزاری که به خوبی میتواند رابطه بین دو متغیر را به لحاظ بصری نمایان کند نمودار پراکنش است. در یک نمودار پراکنش اگر همبستگی بین دو متغیر وجود داشته باشد نقاط بطور تقریبی در امتداد یکدیگر قرار می گیرند. خط رگرسیونی خطی است که از میان نقاط طوری میگذرد که بیش از هر خط دیگری به نقاط نزدیک باشد.
خطای تصادفی است که پراکندگی در تقریب را نشان میدهد و به آن مقادیر باقی مانده Residuals گویند. این مقدار حاصل اختلاف بین مقادیر مشاهده شده و مقادیر پیش بینی شده با مدل در نمونه تصادفی است. در این تکنیک ابزاری که به خوبی میتواند رابطه بین دو متغیر را به لحاظ بصری نمایان کند نمودار پراکنش است. در یک نمودار پراکنش اگر همبستگی بین دو متغیر وجود داشته باشد نقاط بطور تقریبی در امتداد یکدیگر قرار می گیرند. خط رگرسیونی خطی است که از میان نقاط طوری میگذرد که بیش از هر خط دیگری به نقاط نزدیک باشد.
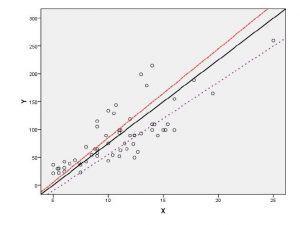
نمودار پراکنش و خط رگرسیون برازش داده شده
بعد از تعیین الگو ، گام بعدی برازش مدل است. در این مرحله راه حلی برای برآورد پارامترهای نامعلوم مدل با استفاده از اطلاعات نمونه می یابیم. رایجترین روش برازش کمترین توانهای دوم است. البته با توجه به مفروضات مسئله روشهای دیگر براورد مانند درستنمایی ماکزیمم میتواند مطرح شود. پس از براورد پارامترهای مدل (ها)، مقادیری که در ازای مشاهدات نمونه ای  برای متغیر
برای متغیر  حاصل می شود مقادیر برازش شده نامیده می شود. در صورتی که مقادیر پیش بینی شده در ازای هر مجموعه از مقادیر متغیر پیشگو محاسبه می شود.
حاصل می شود مقادیر برازش شده نامیده می شود. در صورتی که مقادیر پیش بینی شده در ازای هر مجموعه از مقادیر متغیر پیشگو محاسبه می شود.
مهمترین شرایط برای مدل رگرسیون خطی عبارت است از:
- نرمال بودن باقی مانده ها
- ثابت بودن واریانس باقی مانده ها
- استقلال باقی مانده ها
- عدم وجود همخطی بین متغیرهای پیشگو
به عبارتی باقی مانده ها باید مستقل و با توزیع نرمال با میانگین ۰ و واریانس ثابت باشند.
اعتبار سنجی( Validation)
در تحلیل رگرسیونی پس از برازش مدل به داده ها مناسب بودن مدل برازش شده مورد ارزیابی قرار می گیرد. پیش از هرگونه نتیجه گیری آماری از مدل، مانند پیش بینی، انجام آزمون فرض یا ساختن فواصل اطمینان از ضرایب رگرسیونی، فرض ها و شرایط رگرسیون خطی باید بررسی شوند. هر انحراف از شرایط و مفروضات مدل در خطاهای مدل دیده می شود. بهترین روش برای این که ببینیم مدل رگرسیون تا چه اندازه برای برازش به داده ها خوب است ، رسم نمودار مانده ها می باشد.
مانده یا خطا میزانی از تغییرات در متغیر پاسخ است که با مدل رگرسیون بیان نمی شود. آزمون باقی مانده ها عموما به شکل بصری و با استفاده از نمودارهای هیستوگرام و پراکنش انجام می شود. البته باید توجه شود هنگامی که حجم نمونه کم است هیستوگرام به نظر نرمال نمی آید. در ضمن مقادیر پرت نیز با استفاده از این نمودارها قابل تشخیص خواهد بود.
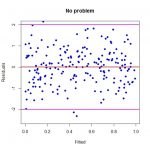
a- نمودار مانده ها با واریانس ثابت
در نمودار مانده ها در مقابل مقادیر برازش شده اگر نقاط حول خط به طور یکنواخت و متقارن پراکنده شده باشند. به ترتیب نشان میدهد الگوی رگرسیون برازش داده شده از لحاظ ثابت بودن واریانس خطاها و میانگین صفر برای خطاها دارای وضعیت مناسبی است. نمودار a نشان دهنده حالتی است که در آن واریانس خطاها ثابت است . (وضعیت مطلوب)
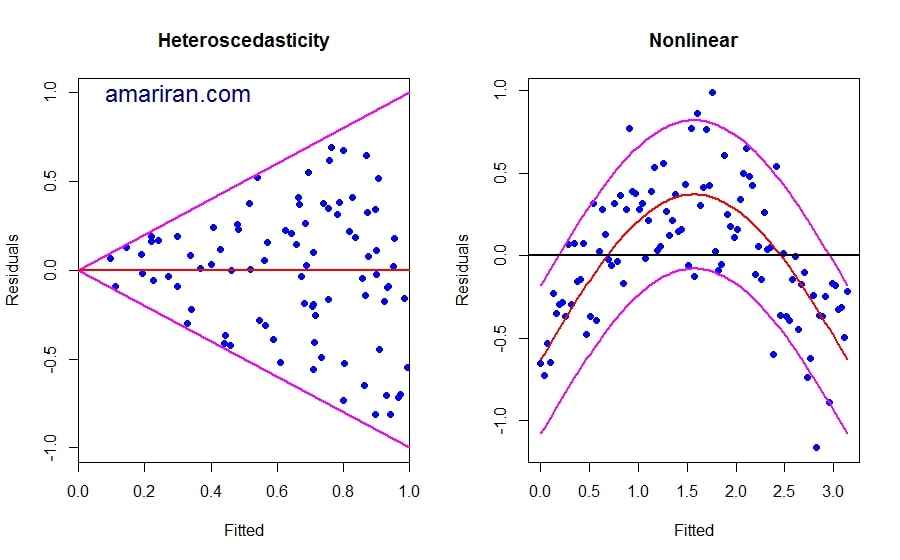
b – نمودار مانده ها با واریانس متغیر
نمودار قیفی شکل ثابت نبودن واریانس را نشان می دهد. هنگامی که فرض واریانس ثابت برای خطاها برقرار نباشد براورد پارامترهای مدل با خطای زیاد خواهد بود در این شرایط دو روش پیش روی تحلیلگر است روش اول بکار بردن کمترین توان دوم وزنی برای براورد ضرایب رگرسیونی و روش دیگر استفاده از تبدیل کننده های واریانس است. در صورتی که نمودار مانده ها در مقابل متغیر پاسخ روند غیر خطی داشته باشد معمولا متغیری به مدل اضافه می شود و یا تبدیلی روی داده ها اعمال می شود. (تبدیل توان دوم یا لگاریتم)
برای بررسی فرض استقلال خطاها نیز می توان نمودار مانده ها در مقابل زمان را بکار برد اگر الگوی خاصی در نمودار مشاهده نشود می توان فرض استقلال مانده ها را تایید کرد. ولی این روش در صورتی قابل استفاده است که ترتیب زمانی مشاهدات گرداوری شده معلوم باشد. بررسی نرمال بودن خطاها نیز با نمودار Q_Q میتوان انجام داد. برای بررسی نرمال بودن خطاها می توان به این نوشته ها رجوع کرد.
بررسی نرمال بودن داده ها با استفاده از نرم افزار SPSS
بررسی نرمال بودن داده ها با استفاده از نرم افزار R
همخطی (Multicollinearity)
مدل از نظر وجود هم خطی بین متغیرهای پیشگو نیز با استفاده از آزمون های همبستگی بررسی می شود. همخطی زمانی روی می دهد که متغیرهای پیشگو همبستگی بالایی داشته باشند. هر چقدر که متغیرهای پیشگو هم خطی بیشتری داشته باشند، خطای براورد پارامترهای مدل نیز بالا خواهد بود. برای تشخیص وجود همخطی در متغیرهای پیشگو، معمولا از مقادیر ویژه ماتریس همبستگی متغیرهای پیشگو و شاخص VIF (عوامل افزایش واریانس، Variance Inflation Factors) استفاده می شود. مقادیر ویژه کمتر از ۰.۰۱ و شاخص VIF بیشتر از ۱۰ را می توان نشان از وجود همخطی در متغیرهای مدل دانست. برای گذر از این مسئله دو رویکرد وجود دارد. در روش اول همخطی داده ها با استفاده از حذف متغیرها از بین می رود. روش دیگر بکار بردن رگرسیون ستیغی Ridge Regression و رگرسیون مولفه های اصلی Principal Component Regression می تواند باشد.
نیکویی برازش ( Goodness of Fit )
گام بعدی در بررسی کفایت مدل برازش شده، معمولا باسنجش میزان رابطه خطی Y و مجموعه متغیرهای مستقل بوسیله نمودار پراکنش Y در مقابل مقادیر برارش داده شده آن انجام می شود. هرچه مجموعه نقاط به خط راست نزدیکتر باشد نشان دهنده رابطه قوی بین متغیرهای مستقل با متغیر پاسخ و مناسب بودن مدل برازش داده شده می باشد. روش دیگر آزمون فرض مربوط به میزان تاثیر گذاری متغیر  به عنوان یک پیشگو برای ، با فرض صفر
به عنوان یک پیشگو برای ، با فرض صفر  است. هرچقدر پی-مقدار آزمون کوچکتر باشد نشان از موثر بودن متغیر در مدل است.
است. هرچقدر پی-مقدار آزمون کوچکتر باشد نشان از موثر بودن متغیر در مدل است.
ضریب تعیین یا  نیز شاخصی است که نسبت کل تغییرات در متغیر پاسخ را که با مجموعه متغیرهای پیشگو بیان می کند. به عنوان مثال مقدار ۸۵. برای نشان می دهد حدود ۸۵% از تغیییرات در متغیر پاسخ را می توان با متغیرهای پیشگو موجود در مدل بیان کرد. در صورتی که مدل برازش خوبی به داده ها باشد این مقدار به ۱ نزدیکتر است. ولی لزوما مقادیر نزدیک به ۱ برای این شاخص نمی تواند نشان اطمینان از مناسب بودن الگوی برازش داده شده باشد و نیاز به تحلیل های گسترده تری دارد.
نیز شاخصی است که نسبت کل تغییرات در متغیر پاسخ را که با مجموعه متغیرهای پیشگو بیان می کند. به عنوان مثال مقدار ۸۵. برای نشان می دهد حدود ۸۵% از تغیییرات در متغیر پاسخ را می توان با متغیرهای پیشگو موجود در مدل بیان کرد. در صورتی که مدل برازش خوبی به داده ها باشد این مقدار به ۱ نزدیکتر است. ولی لزوما مقادیر نزدیک به ۱ برای این شاخص نمی تواند نشان اطمینان از مناسب بودن الگوی برازش داده شده باشد و نیاز به تحلیل های گسترده تری دارد.
تحلیل رگرسیونی در حقیقت فرایندی دوره ای است. در این روش آماری همواره پس اعتبار سنجی مدل با استفاده از خروجی های مدل، به اصلاح مدل پرداخته و این فرایند تا به دست آوردن یک مدل رضایت بخش تکرار می شود. برای بررسی اعتبار یا کفایت مدل معمولا دو راهکار وجود دارد:
- مشاهدات موجود را به صورت تصادفی به دوقسمت تقسیم کرده یک قسمت برای برازش مدل و قسمت دیگر برای بررسی کفایت مدل بکار برده می شود.
- راه دوم استفاده از همه مشاهدات برای مدلبندی داده ها و یافتن یک سری مشاهدات دیگر جهت بررسی کفایت مدل است.
البته روش دوم طرفداران بیشتری دارد. زیرا با کم شدن حجم نمونه قسمتی از اطلاعات ازبین رفته و دقت براوردها کم می شود. در کل بهتر است از تمامی مشاهدات موجود جهت برازش بهترین مدل بهترین مدل ممکن بهره برد. با استفاده از مشاهدات جدید نیز می توان مدل را در یک موقعیت متفاوت بررسی کرد.