
۰۲ مرداد نرمال سازی توزیع داده ها با استفاده از نرم افزار R

برای درک بهتر این متن، می توان نوشته های زیر را مطالعه نمود:
بررسی نرمال بودن توزیع داده ها با استفاده از نرم افزار SPSS
بررسی نرمال بودن توزیع داده ها با استفاده از نرم افزار R
بررسی نرمال چند متغیره بودن توزیع داده ها با استفاده از نرم افزار R
توزیع نرمال مهمترین توزیع های احتمالی در آمار است. در بسیاری از تحلیل های آماری در صورت نرمال بودن توزیع داده ها، روش های آماری بیشتر و کاراتری وجود دارد. اما همیشه شرط نرمال بودن داده ها ممکن است برقرار نباشد. در این حالت یکی از گزینه های پیش رو استفاده از تبدیلات نرمال ساز بر روی داده ها و یا استفاده از روش های آماری است که پیش فرض نرمال بودن توزیع داده ها را نداشته باشد. در این مقاله قصد بر آن است که روش های نرمال سازی توزیع داده ها شرح داده شود.
تبدیل نرمال ساز داده های تک متغیره
یکی از مهمترین تبدیلات نرمال ساز، تبدیل باکس – کاکس (Box – Cox) است. این تبدیل تابعی از پارامتر  است. تبدیل باکس – کاکس عبارت است از:
است. تبدیل باکس – کاکس عبارت است از:
![\[ f(x, \lambda )= \begin{cases} \frac{ x^{\lambda}-1}{\lambda} & \lambda >0 \\ log(x) & \lambda = 0\\ \end{cases} \]](https://amariran.com/wp-content/ql-cache/quicklatex.com-a5b499a1608ae80b61619ec7f46670b6_l3.png "Rendered by QuickLaTeX.com")
فرض می شود که داده های تبدیل یافته دارای توزیع نرمال است و با این فرض تابع درستنمایی احتمال داده ها را محاسبه کرده و سپس براورد درستنمایی ماکزیمم محاسبه می شود. انتظار می رود که داده های جدید حاصل از تبدیل باکس – کاکس با پارامتر به دست آمده دارای توزیع نرمال باشد.
با استفاده از نرم افزار R یک نمونه ۲۰۰ تایی از توزیع کای دو با پارامتر دلخواه شبیه سازی می کنیم. نمودار q-q plot برای این داده ها رسم می کنیم.
x<-rchisq(250,2)
qqnorm(x,pch=19,col=4)
abline(mean(x),sd(x),col=2)
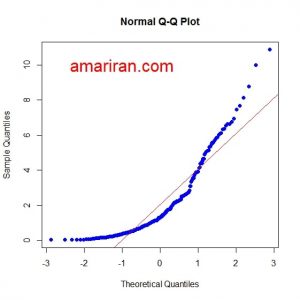
qq plot
همانطور که انتظار می رود، نمودار چندک – چندک انحراف توزیع داده ها از توزیع نرمال را نشان می دهد. اما با استفاده از نرم افزار R مقدار درستمایی پارامتر تبدیل را به دست اورده و سپس داده های تبدیل یافته را محاسبه و نمودار چندک – چندک برای داده های جدید را رسم می کنیم.
boxT<-function(lambda){
if(lambda!=0)y<-(x^lambda-1)/lambda
if(lambda==0)y<-log(x)
lik<-sum(log(dnorm(y,mean(y),sd(y))))
;-lik}
(p<-nlminb(1,boxT)$par)
qqnorm(y<-(x^p-1)/p,pch=19,col=4)
abline(mean(y),sd(y),col=2)
نمودار چندک – چندک برای داده های تبدیل یافته، نشان می دهد که داده های جدید از توزیع نرمال پیروی می کنند. البته برای انجام تبدیل باکس – کاکس می توان از دستور powerTransform نیز استفاده کرد.
x<-rchisq(250,2)
qqnorm(x)
p<-powerTransform(x~1)
qqnorm(y<-x^coef(p),pch=19,col=4)
abline(mean(y),sd(y),col=2)
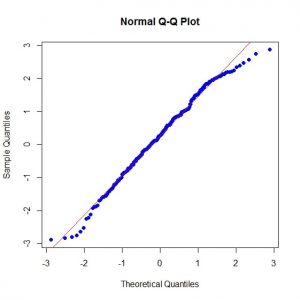
qq plot
- تبدیل باکس – کاکس برای داده هایی مناسب است که دلیل انحراف توزیع داده ها از توزیع نرمال، چوله بودن داده ها باشد. اگر داده ها متقارن باشد و کشیدگی داده ها از کشیدگی توزیع نرمال متفاوت باشد، می توان از تبدیل جان – دراپر استفاده کرد.
- اگر داده ها شامل مقادیر منفی باشد، ابتدا داده ها را به اضافه عددی مثبت (a) کرده به طوری که داده ها همگی بزرگتر از صفر شوند. در این صورت تبدیل باکس – کاکس به صورت زیر است:
![\[ f(x, \lambda )= \begin{cases} \frac{ (x+a)^{\lambda}-1}{\lambda} & \lambda >0 \\ log(x+a) & \lambda = 0\\ \end{cases} \]](https://amariran.com/wp-content/ql-cache/quicklatex.com-a21df35ea58b406bce09065534f0c867_l3.png "Rendered by QuickLaTeX.com")
تبدیل نرمال ساز داده های چند متغیره
در داده های چند متغیره، تبدیل باکس – کاکس را روی هر متغیر اعمال کرده و بردار پارامتر
![\[ \mathbf{\lambda}=(\lambda_1, \lambda_2, \cdots, \lambda_p)\]](https://amariran.com/wp-content/ql-cache/quicklatex.com-b3ef03f91c44e6c07742189e7de10cc0_l3.png "Rendered by QuickLaTeX.com")
را با استفاده از ماکزیمم کردن تابع درستنمایی توام داده ها به دست می آوریم. از آنجا که ماکزیمم کردن تابع درستنمایی در داده های چندمتغیره پیچیده است می توان از تابع درستنمایی اصلاح شده که به صورت زیر تعریف می شود، استفاده نمود که متناسب با لگاریتم (بر پایه عدد نپر – ln) دترمینان ماتریس واریانس – کوواریانس نمونه ای داده های تبدیل یافته است:
![\[ l(\mathbf{\lambda})=-\frac{n-1}{2}\log (|\mathbf{S}^2_\lambda|).\]](https://amariran.com/wp-content/ql-cache/quicklatex.com-77a3c68187315a6530c7d4da9e581013_l3.png "Rendered by QuickLaTeX.com")
برای مثال ۲۰۰ نمونه ۴ متغیره از توزیع غیر نرمال تولید کرده، سپس داده ها را تبدیل می زنیم و نمودار چندک چندک کای دو را برای هر دو مجموعه داده رسم می نماییم. برای اطلاع از طریقه ترسیم نمودار چندک – چندک کای دو و بررسی نرمال بودن داده های چند متغیره می توانید این مقاله را مطالعه کنید.
data<-cbind(rchisq(300,2),rchisq(300,4),rf(300,2,5),rf(300,5,2))
p<-ncol(data)
mu<-apply(data,2,mean)
S<-cov(data)
T<-apply(data,1,function(x)t(x-mu)%*%solve(S)%*%(x-mu))
sT<-sort(T)
n<-nrow(data)
p<-ncol(data)
r<-(1:n)-0.5
qch<-qchisq(r/n,p)
plot(sT,qch,xlab=”Observed quantile”,ylab=”Expected quantile”,
main = expression(Plot~of~chi^2~quantile),col=4,pch=19)
abline(0,1,col=2,lty=2)
text(50,5,”amariran.com”,col=2,cex=1.5)
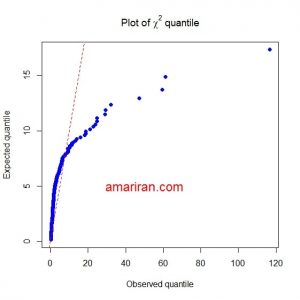
q-q chisquare plot
همانطور که انتظار می رود نمودار چندک – چندک کای دو، انحراف توزیع داده ها را از توزیع نرمال چند متغیره نشان می دهد. با استفاده از تبدیل باکس – کاکس داده ها را تبدیل می زنیم چنانچه توزیع توزیع داده ها به توزیع نرمال چند متغیره نزدیک شود. سپس نمودار چندک – چندک کای دو داده های تبدیل یافته را رسم می کنیم.
data<-cbind(rchisq(300,2),rchisq(300,4),rf(300,2,5),rf(300,5,2))
pow<-powerTransform(data~1)
newdata<-bcPower(data,coef(pow))
p<-ncol(newdata)
mu<-apply(newdata,2,mean)
S<-cov(newdata)
T<-apply(newdata,1,function(x)t(x-mu)%*%solve(S)%*%(x-mu))
sT<-sort(T)
n<-nrow(newdata)
p<-ncol(data)
r<-(1:n)-0.5
qch<-qchisq(r/n,p)
plot(sT,qch,xlab=”Observed quantile”,ylab=”Expected quantile”,
main = expression(Plot~of~chi^2~quantile),col=4,pch=19)
abline(0,1,col=2,lty=2)
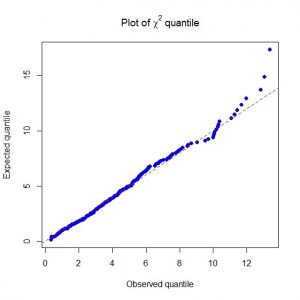
qq plot chisq
نمودار چندک – چندک کای دو برای داده های تبدیل یافته نشان می دهد که داده های جدید دارای توزیع نرمال چند متغیره است.
اشتباهات رایج در مورد نرمال بودن توزیع داده ها:
- اگر تعداد نمونه بیشتر از ۳۰ باشد، توزیع داده ها نرمال است!!!
- با زیاد شدن تعداد نمونه توزیع داده ها به نرمال نزدیک می شود (بنابر قضیه حد مرکزی)!!!
- اگر داده ها را منهای میانگین و تقسیم بر انحراف معیار کنیم، داده ها نرمال می شوند !!!
اینکه اگر تعداد نمونه بیشتر از ۳۰ یا هر عدد دیگری باشد آنگاه توزیع داده ها نرمال است یک اشتباه و سوء برداشتی بیش نیست. بسیاری از مطالعات شبیه سازی بر روی آزمون ها نرمالیتی نشان می دهد که این آزمون ها به ازای تعداد نمونه بیشتر از ۲۰۰ یا ۲۵۰ توان قابل قبولی دارند. اگر تعداد نمونه بیشتر از ۳۰ دارای توزیع نرمال است چرا پس این تحقیقات صورت می گیرد؟ چرا نقاط بحرانی ازمون شاپیرو – ویلک تا تعداد نمونه ۵۰۰۰ محاسبه می شود؟ این برداشت اشتباه از کجا ناشی شده است؟ در آزمون مقایسه میانگین دو گروه وقتی که هر دو گروه داده دارای توزیع نرمال باشند، اگر واریانس گروه ها معلوم باشد، آماره آزمون دارای توزیع نرمال است ولی اگر واریانس ها معلوم نباشد، آماره ای که برای این حالت در نظر گرفته می شود دارای توزیع تی استودنت است. در این حالت آماره آزمون باید با چندک توزیع تی مقایسه شود. ولی به ازای تعداد نمونه بزرگتر از ۳۰، چندک توزیع تی به چندک توزیع نرمال خیلی نزدیک می شود به طوری که می توان در این حالت، آماره آزمون را با چندک توزیع نرمال مقایسه نمود. در اینجا باز هم نرمال بودن توزیع داده ها پیش فرض است و با زیاد شدن تعداد نمونه نه توزیع داده ها نرمال می شود و نه این پیش فرض از بین می رود. همچنین با توسعه نرم افزارهای آماری دیگر چندان تفاوتی در محاسبه چندک های توزیع های مختلف وجود ندارد. بنابراین عملاً استفاده از چندک نرمال به جای تی استودنت دیگر اهمیتی ندارد. در نمودار زیر نزدیکی مقدار چندک توزیع تی به چندک توزیع نرمال به ازای تعداد نمونه بیشتر از ۳۰ به خوبی دیده می شود. خط قرمز چندک ۹۷.۵ درصد توزیع نرمال و نقاط منحنی آبی چندک ۹۷.۵ درصد توزیع تی استودنت با پارامتر n-1 است (n تعداد نمونه).
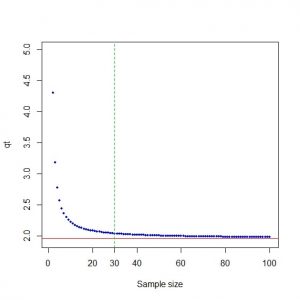
با زیاد شدن تعداد نمونه، طبق قضیه حد مرکزی و تحت شرایطی، توزیع میانگین داده ها به توزیع نرمال گرایش دارد. چه بسا توزیع داده ها مثلاً توزیع تی استودنت باشد که به توزیع نرمال نزدیک است و این تفاوت در توزیع به ازای تعداد نمونه های خیلی بالا آشکارتر گردد.
وقتی از داده های موجود، مقدار میانگین را کم کرده و کل داده ها را تقسیم بر انحراف معیار می کنیم، داده ها استاندارد می شود. بدین مفهوم که میانگین داده ها صفر و انحراف معیار داده های جدید برابر با ۱ می شود. در این حالت توزیع داده ها لزوماً نرمال نیست. اگر توزیع داده ها نرمال باشد، توزیع داده های جدید، نرمال استاندارد است.