
۱۴ تیر بررسی نرمال بودن داده ها با استفاده از نرم افزار R

داده ها و باقیمانده ها در برخی از تحلیل های آماری، باید دارای توزیع نرمال باشند. در اینجا با استفاده از نرم افزار R روش های آزمون نرمالیتی را شرح می دهیم. برای درک بهتر مطالب بررسی نرمال بودن توزیع داده ها و نیز بررسی نرمال بودن داده ها با استفاده از نرم افزار SPSS را مطالعه کنید.
برای بررسی نرمال بودن داده ها ابتدا بهتر است با استفاده از نمودارها و شاخص های آماری، نزدیکی توزیع داده ها به توزیع نرمال را بررسی کنیم. ساده ترین روش ها، رسم نمودار هیستوگرام و جعبه ای برای داده هاست.
به منظور درک بهتر از چگونگی انجام آزمون های نرمالیتی، ابتدا تعدادی داده از توزیع کای دو شبیه سازی کرده و سپس نرمال بودن توزیع داده ها را بررسی می کنیم. انتظار می رود آزمون های آماری معنادار و نرمال بودن داده ها رد شود.
set.seed(10)
x<-rchisq(500,8)
هیستوگرام داده ها به همراه منحنی توزیع نرمال با پارامتر میانگین و انحراف معیار داده ها رسم می کنیم.
hist(x,nclass=20,col=4,freq=F,ylim=c(0,0.13),xlim=c(-5,25))
lines(z<-seq(-5,25,0.01),dnorm(z,mean(x),sd(x)),col=2)
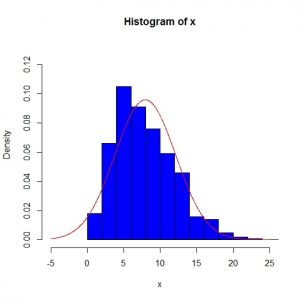
هیستوگرام
اختلاف هیستوگرام داده ها و منحنی توزیع نرمال، نشان از فاصله توزیع داده ها با توزیع نرمال دارد. در بین داده ها اعداد منفی دیده نمی شود در صورتی که احتمال منفی بودن اعداد در توزیع نرمال با میانگین و انحراف معیار داده ها برابر است با:
pnorm(0,mean(x),sd(x))
۰.۰۲۸۱۷۰۷۷
و این نشان می دهد که در بین نمونه ای به اندازه ۵۰۰، انتظار می رود تقریباً ۱۴ داده منفی وجود داشته باشد، در صورتی که همه داده ها در نمونه ما مثبت هستند.
pnorm(0,mean(x),sd(x))*500
۱۴.۰۸۵۳۹
بنابراین در همین ابتدای امر، به نرمال بودن توزیع داده ها می توان مشکوک بود. با این حال سعی می شود بیشتر روش های بررسی نرمال بودن داده ها شرح داده شود. بررسی میزان چولگی و کشیدگی در داده ها گام بعدی در تشخیص نرمال بودن توزیع داده ها می تواند باشد. برای محاسبه چولگی نمونه ای، ابتدا داده ها را استاندارد کرده (داده ها را منهای میانگین و تقسیم بر انحراف معیار می کنیم) و سپس میانگین توان سوم داده ها را حساب می کنیم. برای محاسبه کشیدگی نیز میانگین توان چهارم داده های استاندارد شده را محاسبه و در نهایت حاصل را منهای ۳ می کنیم.
(g1<-mean(scale(x)^3))
۰.۹۳۴۷۴۴۷
(g2<-mean(scale(x)^4)-3)
۱.۶۰۳۹۹۳
در اینجا چولگی تقریباً ۰.۹۳۴ است که از عدد صفر اختلاف دارد. چولگی مثبت است پس داده ها چوله به راست است یعنی تمرکز داده ها بیشتر سمت چپ است. همچنین کشیدگی تقریباً ۱.۶ است که با عدد صفر اختلاف دارد. منحنی داده ها کشیدگی مثبت دارد. قدرمطلق چولگی نباید از حاصل تقسیم جذر اندازه نمونه بر ۴.۸ بیشتر باشد و قدرمطلق کشیدگی نیز نباید از حاصل تقسیم جذر اندازه نمونه بر ۹.۶ بیشتر باشد (توزیع مجانبی چولگی و کشیدگی را بررسی کنید).
qnorm(0.975,0,sqrt(6))
۴.۸۰۰۹۱۲
qnorm(0.975,0,sqrt(6))/sqrt(500)
۰.۲۱۴۷۰۳۳
در اینجا میزان چولگی برابر ۰.۹۳ است که از ۰.۲۱ بزرگتر است. همچنین
qnorm(0.975,0,sqrt(24))
۹.۶۰۱۸۲۳
qnorm(0.975,0,sqrt(24))/sqrt(500)
۰.۴۲۹۴۰۶۶
میزان کشیدگی ۱.۶ است که از ۰.۴۲۹ بسیار بزرگتر است. گام بعد رسم نمودار های احتمال – احتمال و چندک – چندک است. این نمودارها در راستای خطی راست باید باشند. نمودار اول در راستای نیمساز ربع اول و نمودار دوم در راستای خطی راست با عرض از مبدا میانگین داده ها و شیبی برابر با انحراف معیار داده ها.
par(mfrow=c(1,2))
plot(ecdf(x)(x),pnorm(x,mean(x),sd(x)),xlab=”P (empirical)”,main=”Normal P-P Plot”,col=4)
lines(y<-seq(0,1,0.01),y,type=”l”,col=2)
qqnorm(x,col=4)
abline(mean(x),sd(x),col=2)
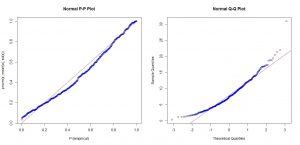
qq plot
دو نمودار فوق نیز نشان از اختلاف توزیع داده ها با توزیع نرمال دارد. در ادامه آزمون های نرمالیتی را با استفاده از نرم افزار R مرور می کنیم. ابتدا آزمون شاپیرو – ویلک که توان بالایی هم دارد انجام می دهیم. این آزمون با دستور shapiro.test قابل انجام است:
shapiro.test(x)
Shapiro-Wilk normality test
data: x
W = 0.95116, p-value = 8.567e-12
با توجه به اینکه مقدار احتمال آزمون (p-value) کمتر از ۰.۰۵ است بنابراین فرض نرمال بودن توزیع داده ها رد می شود. همچنین آزمون کلوموگروف – اسمیرنوف نیز با دستور ks.test قابل انجام است. البته در مقایسه با ازمون شاپیرو – ویلک، توان این آزمون برای بررسی نرمال بودن داده ها زیاد نیست. هرچند اصلاح شده این آزمون برای آزمون نرمالیتی توان بالاتری دارد (آزمون لیلیفورس). البته آزمونی که در SPSS تحت عنوان آزمون کلوموگروف – اسمیرنوف قابل انجام است، همان فرم اصلاح شده این آزمون است.
ks.test(x,”pnorm”,mean(x),sd(x))
One-sample Kolmogorov-Smirnov test
data: x
D = 0.072845, p-value = 0.00992
alternative hypothesis: two-sided
در بسته نرم افزاری nortest آزمون لیلیفورس قابل انجام است:
library(nortest)
lillie.test (x)
Lilliefors (Kolmogorov-Smirnov) normality test
data: x
D = 0.072845, p-value = 1.172e-06
آماره آزمون کلوموگروف-اسمیرنوف و لیلیفورس یکسان است و تفاوت این دو آزمون در محاسبه مقدار بحرانی و مقدار احتمال است. همچنین در بسته nortest آزمون های اندرسون – دارلینگ، کای دو پیرسون، شاپیرو – فرانسیا قابل انجام است. همچنین در بسته fBasics نیز آزمون های دی آگوستینو و جارکو برا را می توان انجام داد.
نتیجه: برای بررسی نرمال بودن داده ها ابتدا با استفاده از ابزارهای توصیفی نظیر هیستوگرام، نمودار جعبه ای، چولگی و کشیدگی داده ها، شرایط نمونه موجود را بررسی و با توزیع نرمال مقایسه می کنیم. در صورتی که نتایج حاصل اختلاف فاحشی با توزیع نرمال نداشت، به سراغ آزمون های فرض می رویم. اگر داده ها شامل داده پرت نباشد و اندازه نمونه نیز کمتر از ۵۰۰۰ باشد از آزمون شاپیرو – ویلک برای بررسی نرمال بودن توزیع داده ها می توان استفاده کرد (این بدان معنا نیست که توان این آزمون برای تعداد نمونه کمتر از ۵۰۰۰ بهتر است بلکه نقاط بحرانی آزمون تا این تعداد نمونه محاسبه شده است). درغیر اینصورت آزمون اندرسون دارلینگ و لیلیفورس گزینه های مناسبی برای بررسی نرمالیتی است.