
۳۰ تیر بررسی نرمال چند متغیره بودن توزیع داده ها با استفاده از R

در بسیاری از تحلیل ها، بررسی همزمان چند متغیر مورد نیاز است. برخی از ویژگی ها و روش های حالت تحلیل چند متغیره مشابه و تعمیم یافته حالت تک متغیره است. از آنجایی که پیش فرض تعداد زیادی از تحلیل های آماری در حالت تک متغیره، نرمال بودن توزیع داده هاست، مطابق انتظار پیروی داده ها از توزیع نرمال چند متغیره نیز پیش فرض برخی از تحلیل های چند متغیره است. از جمله این تحلیل ها MANOVA و  هتلینگ است. برای درک بهتر مطالب می توان به نوشته های زیر رجوع کرد:
هتلینگ است. برای درک بهتر مطالب می توان به نوشته های زیر رجوع کرد:
بررسی نرمال بودن داده ها با استفاده از نرم افزار SPSS
بررسی نرمال بودن داده ها با استفاده از نرم افزار R
نرمال چند متغیره در نرم افزار R
در نرم افزار R و بسته نرم افزاری mvtnorm امکان تولید داده تصادفی از توزیع نرمال چند متغیره و محاسبه چگالی، تابع توزیع و چندک های این توزیع وجود دارد.
library(mvtnorm)
dmvnorm(x, mean = rep(0, p), sigma = diag(p), log = FALSE)
rmvnorm(n, mean = rep(0, nrow(sigma)), sigma = diag(length(mean)),
method=c(“eigen”, “svd”, “chol”), pre0.9_9994 = FALSE)
pmvnorm(lower=-Inf, upper=Inf, mean=rep(0, length(lower)), corr=NULL,
sigma=NULL, algorithm = GenzBretz(), …)
qmvnorm(p, interval = NULL, tail = c(“lower.tail”,”upper.tail”, “both.tails”), mean = 0, corr = NULL,
sigma = NULL, algorithm = GenzBretz(), ptol = 0.001, maxiter = 500, trace = FALSE, …)
library(MASS)
mvrnorm(n = 1, mu, Sigma, tol = 1e-6, empirical = FALSE, EISPACK = FALSE)
بررسی نرمال بودن توزیع داده ها در نرم افزار R
اگر فرض کنیم توزیع بردار تصادفی  نرمال چند متغیره با پارامتر
نرمال چند متغیره با پارامتر  و
و  باشد و همچنین
باشد و همچنین  میانگین نمونه ای و
میانگین نمونه ای و  ماتریس واریانس-کوواریانس نمونه ای داده ها باشد، در این صورت انتظار می رود که
ماتریس واریانس-کوواریانس نمونه ای داده ها باشد، در این صورت انتظار می رود که  دارای توزیع کای دو با
دارای توزیع کای دو با  درجه آزادی باشد. از این نکته برای بررسی نرمال بودن داده ها می توان به سه طریق بهره برد:
درجه آزادی باشد. از این نکته برای بررسی نرمال بودن داده ها می توان به سه طریق بهره برد:
- محاسبه فاصله اطمینان های
 درصد و بررسی اینکه آیا تقریباً درصد از تعداد کل نمونه در این بازه قرار می گیرد یا خیر؟ اگر درصد داده های متعلق به این بازه خیلی کمتر از مقدار مورد انتظار باشد به نرمال بودن توزیع داده ها می توان مشکوک بود.
درصد و بررسی اینکه آیا تقریباً درصد از تعداد کل نمونه در این بازه قرار می گیرد یا خیر؟ اگر درصد داده های متعلق به این بازه خیلی کمتر از مقدار مورد انتظار باشد به نرمال بودن توزیع داده ها می توان مشکوک بود. - محاسبه چندک های توزیع کای دو و مقایسه آن با چندک های نمونه ای آماره فوق و رسم نمودار چندک – چندک (qq plot).
- آزمون های فرض که با استفاده از این آماره و توزیع کای دو طراحی شده اند.
بررسی نرمال بودن توزیع داده های چندمتغیره در R
دو مجموعه داده با استفاده از نرم افزار R شبیه سازی می کنیم، یکی از توزیع غیر نرمال و دیگری از توزیع نرمال چندمتغیره، فاصله اطمینان ۹۵ درصد برای هر کدام از مجموعه داده ها و درصد داده هایی که در بازه قرار می گیرند را محاسبه می کنیم:
data<-cbind(rchisq(300,2),rchisq(300,4),rf(300,2,5),rf(300,5,2))
p<-ncol(data)
mu<-apply(data,2,mean)
S<-cov(data)
T<-apply(data,1,function(x)t(x-mu)%*%solve(S)%*%(x-mu))
q0.95<-qchisq(0.95,p)
mean(T<q0.95)
library(MASS)
data<-mvrnorm(300,rep(0,4),diag(1:4))
p<-ncol(data)
mu<-apply(data,2,mean)
S<-cov(data)
T<-apply(data,1,function(x)t(x-mu)%*%solve(S)%*%(x-mu))
q0.95<-qchisq(0.95,p)
mean(T<q0.95)
مجموعه داده اول شامل یک نمونه ۳۰۰ تایی از چهار متغیر است که هر کدام از متغیرها دارای توزیع کای دو یا فیشر هستند. بنابراین انتظار داریم که درصد داده های قرار گرفته در بازه اطمینان، از ۹۵ درصد کمتر باشد. با تکرار برنامه چون هر بار نرم افزار داده های جدیدی شبیه سازی می کند، درصد ها تغییر می کند اما در اکثر موارد درصد داده های قرار گرفته در بازه اطمینان کمتر از ۹۳ درصد می شود. برای داده های توزیع نرمال چند متغیره نیز در اکثر موارد درصد داده ها نزدیک به ۹۵ درصد است. همچنین چندک های نمونه ای را در مقابل چندهای توزیع کای دو رسم می کنیم. در صورتی که توزیع داده ها نرمال چند متغیره باشد انتظار می رود که نمودار پراکنش چندک ها، تشکیل یک خط راست دهد.
sT<-sort(T)
n<-nrow(data)
p<-ncol(data)
r<-(1:n)-0.5
qch<-qchisq(r/n,p)
plot(sT,qch,xlab=”Observed quantile”,ylab=”Expected quantile”,
main = expression(Plot~of~chi^2~quantile),col=4)
abline(0,1,col=2)
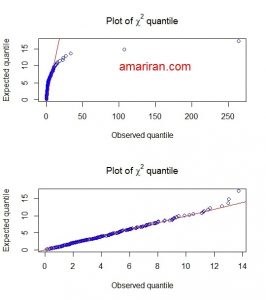
chi square qq plot
در شکل بالا نمودار چندک – چندک کای دو برای دو مجموعه داده رسم شده است. در مجموعه اول که داده ها از توزیع نرمال چند متغیره پیروی نمی کنند، نقاط نمودار ایجاد شده در راستای خط راست واقع نشده است ولی برای مجموعه داده دوم که از توزیع نرمال چند متغیره پیروی می کند، نقاط نمودار حاصل در راستای یک خط راست است.
در برخی از بسته های نرم افزاری R، امکان انجام آزمون هایی برای بررسی نرمال چند متغیره بودن توزیع داده ها فراهم شده است. از جمله بسته mvnormtest که امکان انجام آزمون شاپیرو – ویلک چند متغیره وجود دارد.
library(mvnormtest)
data(EuStockMarkets)
C <- t(EuStockMarkets[15:29,1:4])
mshapiro.test(C)
همچنین در بسته MVN امکان انجام آزمون Henze-Zirkler، Mardia و Royston فراهم شده است.